I'm an applied scientist at Amazon Ring AI. I obtained my PhD in Computer Science from CGVLab at Purdue University, advised by Prof. Daniel Aliaga. Before coming to Purdue, I recieved my B.S. in Computer Science from Zhejiang University. I interned at Qualcomm in summer 2021, and worked as a research intern at Adobe in summer 2022 & 2023 & 2024. During my internships, I'm fortunate to work with Dr. Meng-Lin Wu, Dr. Zhifei Zhang, Dr. Wei Xiong and Dr. Zhe Lin.
I'm interested in GenAI topics, including building diffusion models for image and video generation (especially on identity preservation), and designing MLLMs for video understanding.
I'm always open to research collaborations. Please feel free to reach out.
Kubrick (video generation agent) has been accepted to CVPR 2025 AI4CC Workshop.
03-2025
Passed my PhD thesis defense!
01-2025
Refine-by-Align (A model to refine/fix generative artifacts from any generated images) has been accepted to ICLR 2025 .
09-2024
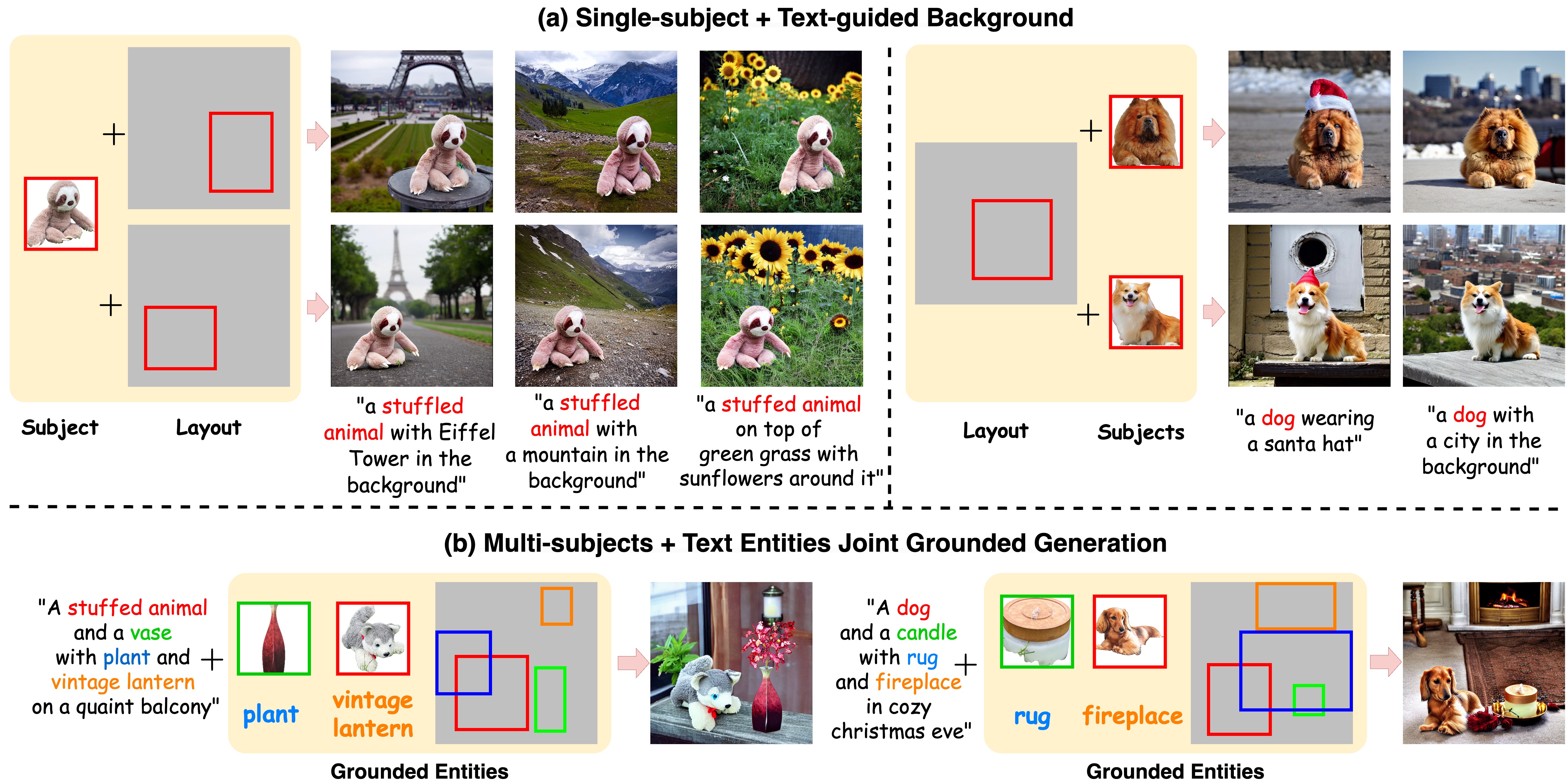
We release GroundingBooth , an image customization model with finegrained layout control.
08-2024
We release Kubrick , the first multimodal agent-based video generation pipeline.
07-2024
Thinking Outside the BBox (a generative model that automatically drops & harmonizes foreground objects in background images at reasonable locations) has been accepted to ECCV 2024 .
02-2024
IMPRINT (the state-of-the-art model for image customization / object dropping) has been accepted to CVPR 2024 .
We present MMIG-Bench, a comprehensive benchmark for evaluating multi-modal image generation models. MMIG-Bench unifies compositional evaluation across T2I and customized generation, introduces explainable aspect-level metrics, and offers a thorough analysis of SOTA diffusion, autoregressive, and API-based models (e.g., GPT-4o, Gemini).
MLLMs struggle with accurately capturing camera-object relations, especially for object orientation, camera viewpoint, and camera shots. To address this, we propose a synthetic generation pipeline to create large-scale 3D visual instruction datasets. MLLMs fine-tuned on our dataset outperform commercial models by a large margin.
We introduce a new task: reference-guided refinement of generative artifacts. Given a synthesized image, a reference and a free-form mask marking the artifacts, the model automatically identifies the correspondence in the reference and extracts the localized feature, which is then used to fix the artifacts.
We introduce GroundingBooth, a framework that achieves zero-shot instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task.
We build the first multimodal agent-based video generation pipeline through 3D engine scripting. Given any text prompt, multimodal agents collaborate to produce detailed Blender scripts to generate video with plausible character and motion consistency in any length.
Our tuning-free model achieves advanced image composition with a decent identity preservation, automatic object viewpoint/pose adjustment, color and lighting harmonization, and shadow synthesis. All these effects are achieved in a single framework!
We introduce a novel task, unconstrained image compositing, where the generation is not bounded by the input mask and can even occur without one (thus supports automatic object placement). This allows the generation of realistic object effects (shadows and reflections) that go beyond the mask while preserving the surrounding background.
We define a novel task: generative image compositing, and present the first diffusion model-based framework, ObjectStitch, which can handle multiple aspects of compositing such as viewpoint, geometry, lighting and shadow together in a unified model.