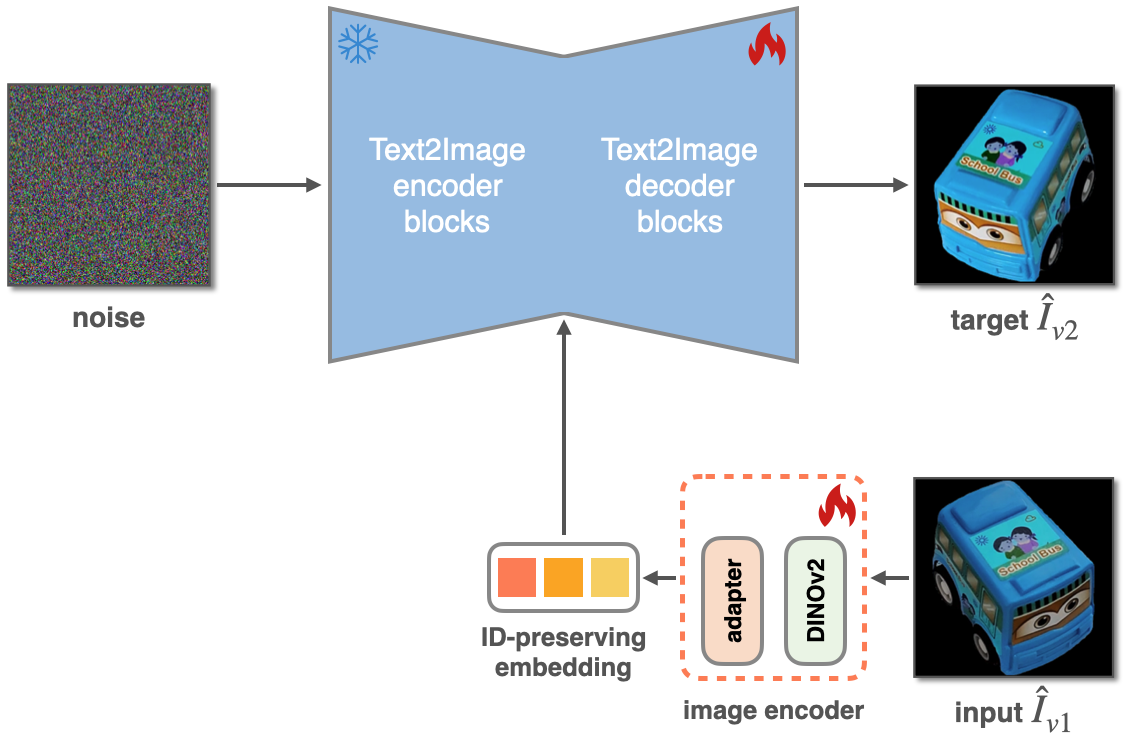
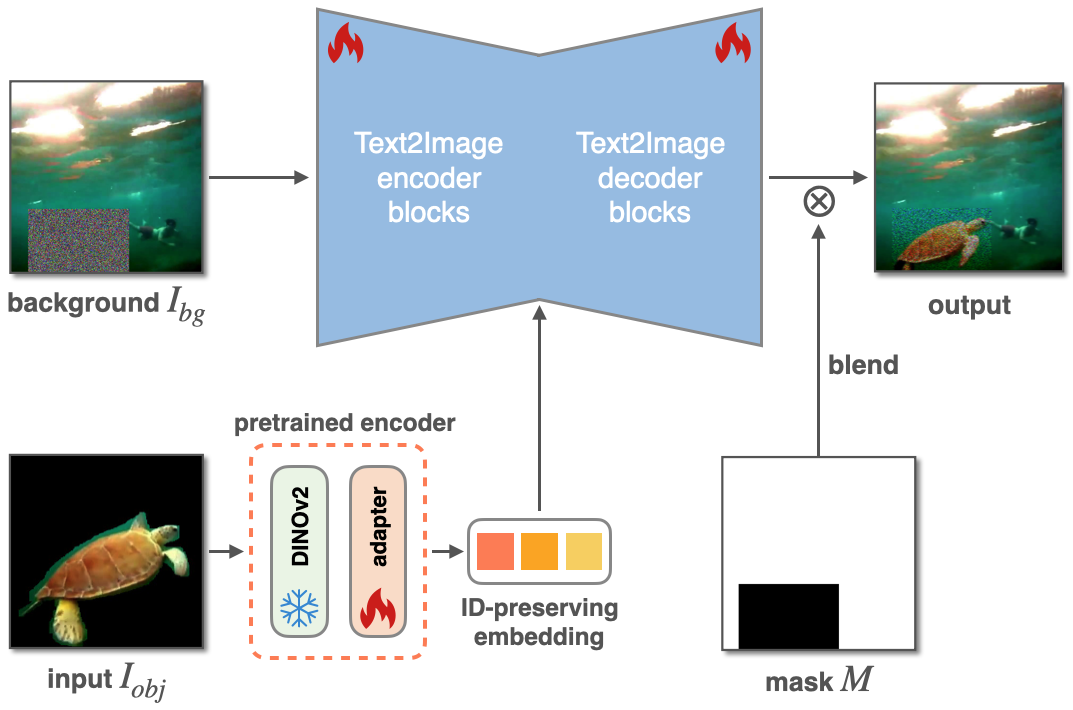
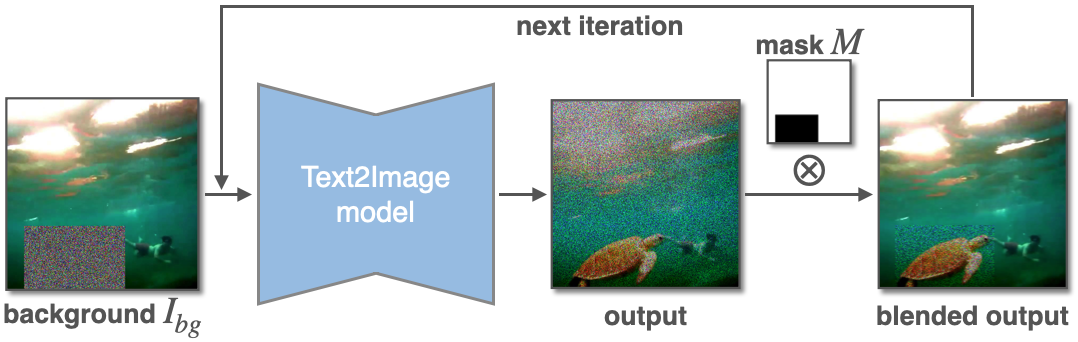
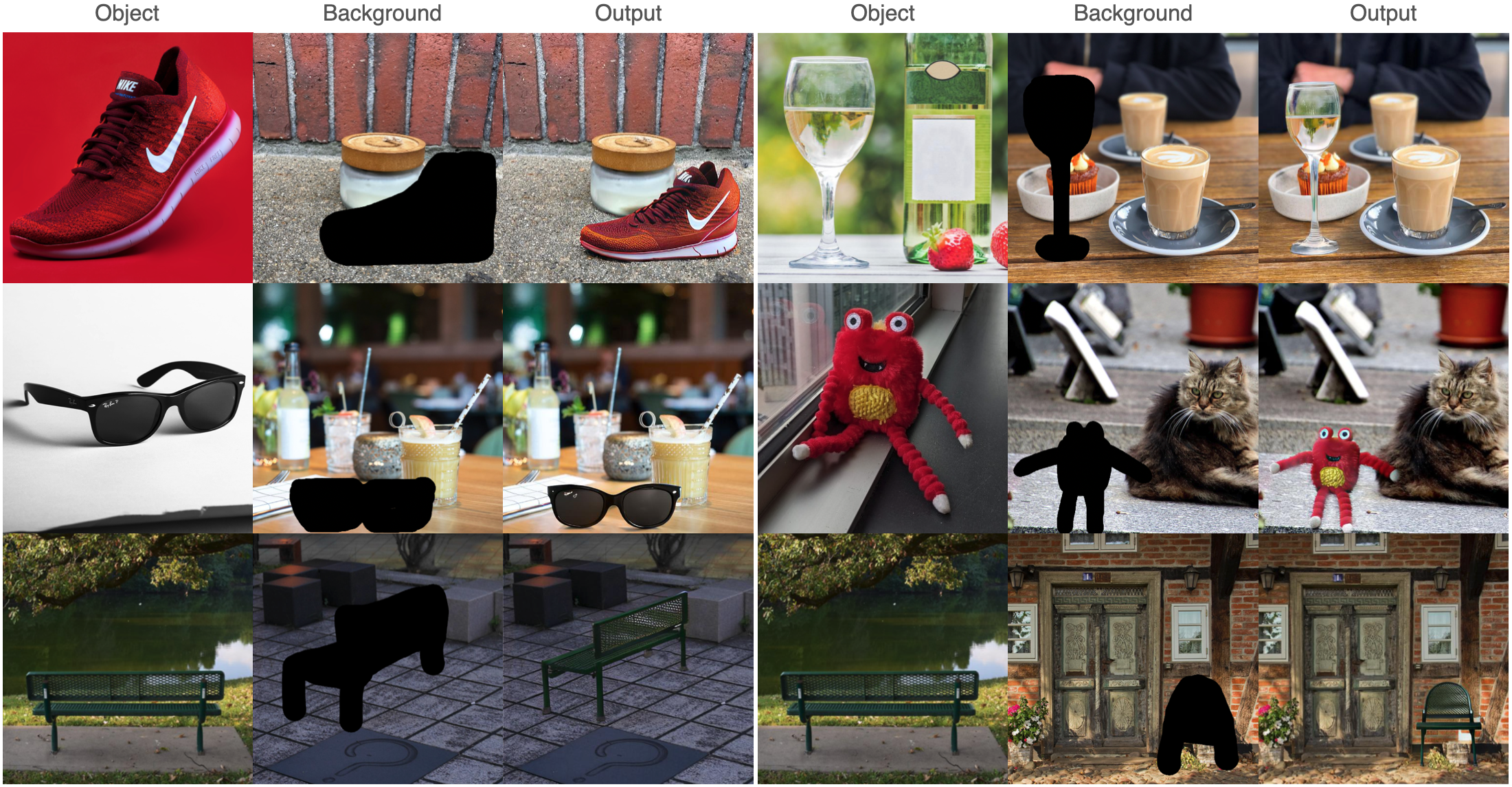
Figure 1. Top: Comparison with three prior works, i.e., Paint-by-Example, ObjectStitch, and TF-ICON. Our method IMPRINT outperforms others in terms of identity preservation and color/geometry harmonization. Bottom: Given a coarse mask, IMPRINT can change the pose of the object to follow the shape of the mask.